site navigation
Maschinelles Lernen
WS 97/98, (basierend auf der Vorlesung von Prof. Wysotzky, TU-Berlin)
Lernen wird definiert als Verbesserung eines informationsverarbeitenden
Systems hinsichtlich eines Gütefunktionals
Man unterscheidet zwischen überwachten und unüberwachten
Lernen
Zum überwachten Lernen zählt das Begriffslernen
, zum unüberwachten Lernen durch
Entdecken
Inhalt:
Begriffslernen
Lernen durch Entdecken
Lernen durch Umstrukturierung
Überblick: (Versuch)
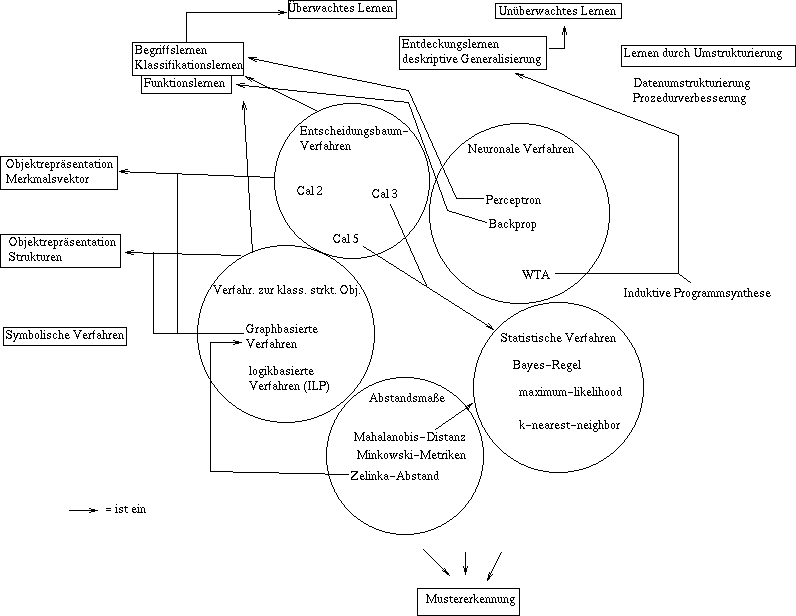
Begriffslernen (Klassifikationslernen)
-
die Verfahren sind Metaalgorithmen, da sie Klassifikationsverfahren konstruieren
.
-
Eingabe sind Paare von Merkmalsbeschreibungen und Klassen oder Funktionen
(Vektoren) bestehen die Klassen aus Vektoren, liegt Funktionslernen vor,
z.B. Backpropagation.
Es gibt Symbolische Verfahren wie z.B.
oder man kann Künstliche
Neuronale Netze verwenden
Lernen durch
Entdecken
Entdeckende Lernverfahren haben als Trainingsmenge nur Merkmalsvektoren
oder Terme (keine Klassen)
Sie treffen eine Klassifizierung selbstständig durch Mustererkennung
oder heuristische Ansätze (z.B. WTA)
oder allgemein durch Strukturerkennung( z.B. induktive
Programmsynthese)
Lernen
durch Umstrukturierung
-
Einbau von neuem Wissen (Assimilation)
-
Umstrukturierung der Daten (Akkomodation)
-
Transformation von Prozeduren und Wissen zur Effektivierung des Zugriffs
Beispiele:
Entscheidungsbaumverfahren
|
Cal 2 |
Cal 3 |
Cal 5 |
| Merkmale |
diskret |
diskret |
kontinuierlich |
| Trainingsmenge |
disjunkt |
nicht disjunkt |
nicht disjunkt |
Cal 3 und Cal 5 sind statistische Verfahren
Cal 2 baut einen (zu Anfang
leeren, mit * gekennzeichnet) Entscheidungsbaum aus einer Trainingsmenge
auf, indem diese Menge sequentiell durchgegangen wird und die Ausgabe des
bisherigen Klassifikators mit der tatsächlichen Klasse verglichen
wird.
Es können 3 Fälle auftreten
-
Es gibt Übereinstimmung
-> nichts wird verändert
-
An dem Baum hängt ein *
-> die Klasse wird eingetragen
-
Es steht eine falsche Klasse da -> das nächste Merkmal
wird hinzugezogen
Das Verfahren terminiert, wenn die Trainingsmenge disjunkt war
Es wird immer richtig klassifiziert, wenn alle für das Problem
relevanten Fälle in der Trainingsmenge vorhanden waren
Der fertige Baum kann dann (eventuell nach Umstrukturierung) durch
Eliminierung von Irrelevanzen und Redundanzen noch vereinfacht werden.
-
(bedingt/global) irrelevante Merkmale sind solche, von denen die
Klassifizierung nicht abhängt, wenn etwa an allen Ausprägungen
dieselben Teilbäume (Klassen) hängen.
-
bedingte Redundanz ist immer dann gegeben, wenn im fertigen Baum
noch ein * auftaucht, dies bedeutet, das für diesen Weg im Baum (für
dieses Objekt) kein Beispiel gegeben war. Die Ausprägung dieses Merkmals
war dann durch die Ausprägungen voriger Merkmale vollständig
determiniert und kann weggelassen werden.
-
bedingt vs. global bedeutet in diesem Zusammenhang den Unterschied,
ob eine Merkmal in jedem Fall irrelevant ist oder nur für eine bestimmte
Ausprägung eines anderen Merkmals (weiter oben im Baum)
Dies entspricht Lernen durch
Umstrukturierung
Welche Merkmalsreihenfolge am günstigsten ist, kann vor der Baumerzeugung
durch Berechnung der Transinformation der Merkmale bestimmt werden
Cal 3
Oft ist eine eindeutige Klassifizierung nicht möglich:
-
die Attribute reichen für eine eindeutige Klassifizierung nicht aus
-
die Trainingsmenge ist aufgrund von Störungen nicht disjunkt
Cal 3 ist ein Verfahren zur statistischen Klassenbildung. Der Baum wird
dabei nicht bei jedem Fehler geändert, sondern es werden die Häufigkeiten
der Klassen registriert.
Das Verfahren benötigt dazu zwei Parameter:
-
eine Zahl R wieviele Objekte zur Entscheidung gebraucht werden
-
eine Schwelle 0.5 < S < 1 , ab der für eine Klasse entschieden
wird. Der Klassifikationsfehler ist dann immer < 1-S
Liegen bei R Objekten die Häufigkeiten aller Klassen unter S, wird
das nächste Merkmal hinzugezogen
Sind die Kosten für die Fehlentscheidung für eine Klasse
höher als eine für eine andere, kann jeder Klasse ein Kostenfaktor
gegeben werden, die Wahrscheinlichkeiten werden dann mit diesem multipliziert.
Cal 5 ist ein Klassifikationsverfahren
für reellwertige Daten.
Es sucht eine Menge von Intervallen über ein kontinuierliches
Merkmal und versucht, pro Intervall eine Dominanzentscheidung zu treffen
Das funktioniert nach folgenden Schritten:
-
alle Beispiele der Trainingsmenge nach aufsteigender Ausprägung des
Merkmals sortieren
-
das nächste Beispiel dem aktuellen Intervall hinzufügen, gibt
es Dominanz einer Klasse, Intervall abschließen
-
sukzessive aller Nachbarintervalle gleicher Klassen vereinigen
-
bei allen Intervallen mit Nichtdominanz nächstes Merkmal nehmen
Dafür wird auch wieder eine Schwelle S benötigt, liegt sie innerhalb
eines Konfidenzintervalls, wird auf Dominanz entschieden
Auch hier können verschieden hohe Kosten für die Klassen
angegeben werden
Lernen (Induktion) im PK1
Induktive logische Programmierung (ILP)
-
Die Objekte bestehen aus logischen Formeln. Für jede Klasse wird eine
Menge von Prototypen gesucht. Ein Prototyp wird durch alle Objekte einer
Klasse generalisiert, aber durch keines der Gegenklasse.
-
Ein Objekt wird für eine Klasse entschieden, wenn es einen Prototypen
dieser Klasse gibt, den das Objekt generalisiert, aber keinen Prototyp
der Gegenklassen.
-
Vorwissen kann dabei eingebracht werden (die Menge der Beschreibungen kann
erweitert werden)
-
der Prototyp für eine Klasse (gegeben eine Menge von Beschreibungen)
entspricht der maximalen Generalisierung dieser Beschreibungen. (Suche
der Maxclique im Kompatibilitätsgraphen (Verträglichkeitsgraph)
, z.B durch WTA-Netz)
Die Prototypen sind nicht eindeutig
graphbasierte
Verfahren
strukturierte Objekte können durch eine relationale Algebra (logische
Terme) und markierte Graphen dargestellt werden. Diese werden intern (z.B)
als Adjazenzmatrix dargestellt.
-
Die Zuordnung der Knoten in den Diagonalelementen ist dabei nicht eindeutig,
es gibt n! mögliche Anordnungen.
-
Zwei Graphen sind isomorph, wenn es eine Permutation der Adjazenzmatrizen
gibt, die sie gleich werden läßt.
-
Beim Erkennen der Graphen, z.B. um Prototypen zu finden, muß deshalb
immer ein Isomorphietest durchgeführt werden.
-
Die Komplexität des Tests (NP-Vollständig) kann reduziert werden,
indem Kontextmerkmale zu den Knoten hinzugenommen werden (z.B. Zahl der
ein- und auslaufenden Kanten).
-
Dies kann z.B. durch das Weissfeilersche Verfahren berechnet werden, das
die Matrizen quadriert. Je nach Kontexttiefe N (wie oft quadriert wurde),
stehen dann in den Diagonalelementen die Wege der Länge N von den
Knoten. (gilt natürlich auch für die Kanten in den Nichtdiagonalelementen).
Die Knoten können dann in Kontextklassen zusammengefasst werden, gibt
es K Klassen, reduziert sich der Aufwand des Isomorphietest von n! zu Prod(i=1:K)
n_i !
-
Die Knotenmerkmale können auch in Merkmalsvektoren übertragen
werden, mit denen dann ein entsprechendes Klassifikationsverfahren
(z.B. Cal 2) klassifizieren kann.
Zum Vergleich zweier Graphen kann der Zelinka-Abstand
verwendet werden d(G1, G2) = max(k(G1), k(G2)) - k(ggg(G1,G2)), wobei k(x)
die Knotenanzahl und ggg(x1,x2) die größte gemeinsame Generalisierung
ist.
Graphvergleiche (matching) können auch durch neuronale Netze bewerkstelligt
werden (WTA).
statistische Klassifikation
Ein Klassifikator ordnet einem Eingabevektor einer Klasse zu. Die Eingabevektoren
können dabei als Punkte in einem n-dimensionalem Merkmalsraum dargestellt
werde. Idealerweise stellen die einzelnen Klassen Punktwolken in diesem
Raum dar (dann können sie durch einen linearen Klassifikator wie Perceptron
getrennt werden) , die durch Trennebenen möglichst eindeutig zu trennen
sind. Prototypen der Klassen sind dabei in der Regel die Mittel- (Erwartungs-)werte
der Wolken. Es können dann z.B. Abstandsmaße
zur Klassifikation verwendet werden. In diesem Fall kann auch die k-nearest-neighbor-Methode
verwendet werden, bei der ein Element immer der Klasse seines nächsten
Nachbarn (ausgehend von den Prototypen) zugeteilt wird. Diese Methode approximiert
die Trennebenen für mehrere Klassen stückweise linear.
Weitere statistische Verfahren:
-
ist die bedingte Wahrscheinlichkeitsdichte für (x | k_i) einer Klasse
k_i sowie die a-priori-Wahrscheinlichkeit dieser Klasse bekannt,
kann nach der Bayes-Regel entschieden
werden (wenn p(k_i) p(x | k_i) > p(k) p(x | k) , dann entscheide k_i).
-
Sind die A-Priori- Wahrscheinlichkeiten alle gleich, heißt diese
Regel Maximum-likelihood
-
ein weiteres statistisches Verfahren ist die Mahalanobis-Distanz
Künstliche Neuronale
Netze sind z.B.
Sie modellieren verschieden Aspekte der menschlichen Neuronen
Grundsätzlicher Aufbau eines Neurons ist
-
eine Menge von gewichteten Eingabewerten,
-
eine Funktion, die diese zusammenfasst (in aller Regel die Summenfunktion)
-
eine Outputfunktion ( z.B. Signumfunktion, Rampenfunktion, logistische
Funktion) und
-
eine Schwelle Theta, ab der das Neuron feuert
Es gibt immer zwei Phasen, Lernphase (z.B. Hebb'sche
Lernregel) und Anwendungsphase.
Will man einen Ausgabevektor haben, braucht man ein neuronales Netz.
Ein Perceptron ist
ein Automat, der eine 1 ausgibt, wenn die Summe der gewichteten Eingänge
eine Schwelle Theta überschreitet, und sonst eine 0. (Minsky
und Papert) Er ist damit eine binärer Klassifikator
Der Lernalgorithmus für den Spezialfall d=0 und | x | = 1 lautet:
Setze w mit | w | > 0 beliebig
bis alle Objekt richtig klassifiziert wurden:
neues Objekt anbieten
wenn x elem k1 und wx >
0 oder x elem k2 und wx < 0
tue nichts
sonst
wenn x elem k1 und wx < 0
w = w+x
wenn x elem k2 und wx > 0
w = w-x
done
done
done
-
Die Klassen müssen disjunkt sein
-
Die Schwelle d kann in den Gewichtsvektor gezogen werden, wenn man x_n+1
= 1 (Bias) und w_n+1 = d setzt
-
Der Lernalgorithmus terminiert, wenn es einen Einheitsvektor w* und eine
Zahl d>0 gibt, mit w* x > d für alle x elem k1 und w* x < d für
alle x elem k2 (die Klassen sind linear separierbar) (Konvergenztheorem
des Perceptronalgorithmus)
-
Die geometrische Interpretation besagt, das w ein Vielfaches eines
Normalenvektors der Trennebene ist, alle Objekte der einen Klasse liegen
in dem Halbraum, in den w zeigt, alle Objekte der anderen im entgegengesetzten
Halbraum
-
Der Algorithmus läßt sich auch auf nicht linear separierbare
Probleme anwenden (allerdings ohne Konvergenzgarantie), indem man die Änderung
für die i'te Iteration mit 1/i gewichtet
-
Das Perceptron heißt dann auch adaline (adaptive linear neuron)
Backpropagation
-
gegeben ist eine Trainingsmenge von Ein- und Ausgabevektoren, gesucht wird
eine Gewichtsmatrix.
-
Das Netz besteht aus Schichten von Neuronen, die alle miteinander verbunden
sind, der Output eines Neurons berechnet sich dabei durch o_i = f(sum_j(o_j
w_ji) - theta_j).
-
Als Outputfunktion werden nichtlineare Funktionen wie der tanh oder die
Fermi-Funktion f(x) = 1/(1+exp(-x)) genommen.
-
Die Theta werden in die Summe gezogen, indem sie Gewichte von Bias-Units
sind (Output const 1)
-
Der Fehler E=1/R sum_r(sum_j(1/2sqr(yt_j-y_j))) (mittlere Summe der halben
Fehlerquadrate über alle Patterns) soll dabei minimiert werden
-
dies geschieht durch Nullsetzen der Ableitung des Fehlers nach den Gewichten
-
da die direkte Lösung problematisch ist, werden die Gewichte schrittweise
so verändert, das der Fehler geringer wird (Gradientenabstiegsmethode).
Die Folge der W_ij konvergiert dann im statistischen Mittel gegen die Lösung
(Methode der stochastischen Approximation).
-
die delta-Regel besagt dabei, das das Fehlersignal eines Knotens
nur von dem der Nachfolger abhängt, der Abstand der Gewichte
Delta w = -gamma dE/dw_ji ist (wobei gamma die Sprungweite des Abstiegs
ist), b.z.w Delta w = gamma delta_j o_i ist, wobei delta_j für
die hinterste Schicht = f'(net_i)(t_pi - o_i) ist und für die vordenen
delta_k = f'(net_k)sum(delta_j w_jk) gilt.
-
Dies kann über mehrere Schichten gehen, auch "Hidden Units" (mehr
als In- und Outputschicht), die Gewichtsänderungen werden beim Lernen
von hinten nach vorne berechnet ("zurückpropagiert")
-
Die Trainingsbeispiele können dabei gleichzeitig (Batchlearning,
learning-by-epoch) oder nacheinander angeboten werden
Winner Takes
All-Netze
-
Ein WTA-Netz ist ein Modell eines Neurons mit erregenden und hemmenden
Synapsen.
-
Die Erregung jeden Neurons berechnet sich beim Lernen durch die Gleichung
p_i(t) = p_i(t-1)(1-d) + sum_j(w_ij * p_j)
-
Meistens gibt es noch eine Outputfunktion (Rampenfunktion) : f(p_i) = 0
<- p_i < 0, 1 <- p_i > 1, p_i sonst
-
Das Netz ist stabil, wenn einige Knoten "gewonnen" (=1) haben und andere
"verloren" (=0) haben
-
Die Parameter d (für die Selbsthemmung), Wi und W (für hemmende
und erregende Kanten) spielen für die Konvergenz des Netzes eine große
Rolle.
-
Anwendung ist z.B. das Finden von Maxclique im Kompatibilitätsgraphen.
-
eine weitere Anwendung ist die Zuordnung von Buchstabengruppen zu Lautsymbolen
(nettalk)
die Induktive Programmsynthese
verwendet eine Trainingsmenge, die die extensionale (vollständige)
Beschreibung eines rekursiven Programms darstellt, um daraus mittels eines
Klassifikators eine intensionale Beschreibung zu generieren (ein RPS, rekursives
Programm Schema)
Klassifikation
durch Abstandsmaße
Muster können als Merkmalsvektoren in einem n-dimensionalem Merkmalsraum
dargestellt werden.
Ähnlicheit zwischen Mustern kann dann durch Abstandsmaße
bestimmt werden, was sowohl zum Entdeckungs- wie zum Klassifizierunglernen
benutzt werden kann.
-
Euklidische Distanz d(x,y) = sqrt(sum(sqr(x_i - y_i)))
-
Minkowski-Metrik: Verallgemeinerung der Euklidischen Distanz von
2 auf n
-
Mahalanobis-Abstand: die Abstände
werden mit der inversen Kovarianzmatrix gewichtet: d(x, y, C) = sqrt((x-y)
C^-1 (x-y)). Die Vektoren müssen aus einer Verteilung stammen,
deren Dichte bekannt ist. Dabei werden die Achsen von Merkmalen mit großer
Streuuung gestaucht, während die mit geringer Streuung gedehnt werden.
-
Zelinka-Abstand
Durch eine Transformationsmatrix kann ein Input x_i in einen Output y_j
transformiert werden, wenn y_j = sum_i(W_ij xi) gilt. Die Matrix stellt
dann ein assoziatives Gedächtnis dar (Lernmatrix), sie kann
durch die Hebb'sche Lernregel
berechnet werden, die besagt, das die Gewichte eines feuernden Neurons
stärker werden: w_ji(t+1) = w_ji(t) + eta y_j x_i, wobei eta
eine Proportionalitätskonstante ist (Lernrate).
Zur Mustererkennung werden oft neuronale
Netze verwendet
author: Felix Burkhardt