site navigation
Das Text2Speech System Siphon
Vorwort
Siphon habe ich im SS 1997 im Rahmen eines Projektes geschrieben.
Es diente für mich als Einstieg in die TTS-Problematik und
hat keinen praktischen Wert (unten auf der Seite kann man ein Demo hören). Ich schreibe dies, weil es tatsächlich
Leute gibt, die den Quelltext runterladen
Falls hier jemand ein deutschsprachiges TTS-System sucht: Ich empfehle MBROLA.
Inhalt
Einleitung
Phonemisierung
Signalgenerierung
Inventar
Silbeninventar
Sampleinventar
Einleitung
SiPhon ist ein ein text2speech System
für die deutsche Sprache. Es heisst SiPhon weil es Silben und
Phoneme miteinander konkateniert.
Wie alle t2s-Systeme besteht es grundsätzlich aus zwei Stufen;
die erste konvertiert die Eingabe von orthographischer Repräsentation
in Lautschrift und die zweite generiert aus dem Output ein Sprachsignal
(in diesem Fall durch Verkettung gegebener Samples).
 Die Konversion geschieht einfach durch das Suchen nach Silben durch
Vergleichen mit einer Konversionstabelle.
Output der ersten Stufe ist eine Liste von Silben. Einer der Vorteile
dieses Ansatzes ist es, das die Transkription und das Finden von
Silbengrenzen in einem Schritt geschehen, was für die Phonemisierung
und Signalgenerierung insofern von Bedeutung ist, als dass sich
Aussprachephänomene hauptsächlich innerhalb von Silben
abspielen, zudem benötigt man Silbeninformation für die
Akzentsetzung.
Die Konversion geschieht einfach durch das Suchen nach Silben durch
Vergleichen mit einer Konversionstabelle.
Output der ersten Stufe ist eine Liste von Silben. Einer der Vorteile
dieses Ansatzes ist es, das die Transkription und das Finden von
Silbengrenzen in einem Schritt geschehen, was für die Phonemisierung
und Signalgenerierung insofern von Bedeutung ist, als dass sich
Aussprachephänomene hauptsächlich innerhalb von Silben
abspielen, zudem benötigt man Silbeninformation für die
Akzentsetzung.
Phonemisierung
Beginnen wir die Erklärung mit der phonetischen Transkription:
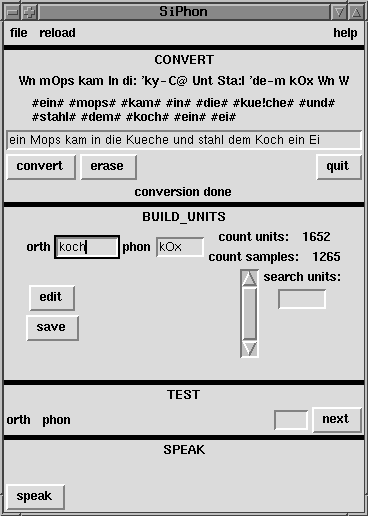
Schritt 1: erase non-alphabetical characters
nicht-alphabetische Zeichen aus dem Input zu eliminieren ist notwendig,
um Programmabstürze durch unbeabsichtigt interpretierte Sonderzeichen
zu vermeiden, jedoch sollten vorher durch Satzzeichen gegebene
Satzstrukturinformationen extrahiert werden.
Dieser Teil wird geändert, wenn suprasegmentale Intonation auf
Satzebene hinzugefügt wird (z.B. F0-Absenkung bzw. Anhebung bei
Aussage bzw. Fragesätzen).
Schritt 2: eliminate capitalisation
Im allgemeinen ist Gross-/Kleinschreibung für die Transkription
eines Wortes unwichtig, allerdings geht damit Information über
die Wortart verloren (Nomen oder Adjektiv), was durchaus von
Belang sein kann
(zum Beispiel <weg> -> /vEk/ aber <Weg> -> /ve:k/
Schritt 3: split composita
Dies ist notwendig, da durch Komposita viele Regeln zur Konvertierung
ausser Kraft gesetzt werden
Man sollte eigentlich auch Suffixe wie zB. <ge> oder <ver>
markieren, aber dafuer bräuchte man Information über die
Wortart (eine weitere Wortliste).
Schritt 4: mark special situations
Da es keine expliziten Konvertierungsregeln gibt, müssen spezielle
Situationen, in denen es Einflüsse über Silbengrenzen
hinweg gibt, markiert werden.
Zur Zeit gibt es fünf Markierungen:
- # markiert die Wortgrenzen.
- ! markiert eine VCV-oder VCCV-Gruppe (<gute> -> <gu!te>).
Das Programm könnte sonst z.B. nicht zwischen <gut> und
<gu-te> unterscheiden (es würde zu <gut-e> konvertieren)
Die Markierung kann auch zwischen zwei Konsonanten liegen:
<gern> vs. <ger-ne>
- = markiert hintere Vokale vor <ch> über Silbengrenzen hinweg:
(<oche> -> <o=che>), sonst könnte es nicht zwischen
/kO-x@/ und /kO-C@/ untescheiden
- § markiert Doppelkonsonanten (<alle> -> <a§lle>) um über
Vokalqualität und Länge zu entscheiden.
sonst wüsste es nicht, ob es <rolle> mit
/RO-l@/ oder /Ro-l@/ transkribieren sollte
- + markiert <n> vor <k> (<nk> -> <n+k>) um die korrekte
Transkription von zB. <danke> zu /daN-k@/ garantieren (vs. /dan-k@/)
Schritt 5: actual conversion
dies ist ein sehr einfacher (wenn auch nicht sehr effizienter)
Algorhitmus, der aus einer Konversionstabelle den längsten passenden
Eintrag heraussucht
Um zB. das Wort <taschentuch> zu transkribieren, sollte es die
folgenden Einträge finden
|
ta!
|
ta
|
|
schen
|
S@n
|
|
tuch
|
tux
|
output ist dann die Liste {ta S@n tux}
Schritt 6: set accents
Da Akzentuierungsregeln sinnvollerweise morphologisch
motiviert sind, das Programm jedoch bisher über keinerlei
morphologische Wissensbasen verfügt, ist eine halbwegs
korrekte Akzentuierung nicht möglich.
(Da sie aber schon fär die Verständlichkeit
unabdingbar ist, habe ich sie hier vorgesehen)
Signalgenerierung
Der zweite Schritt ist bisher noch weit weniger komplex:
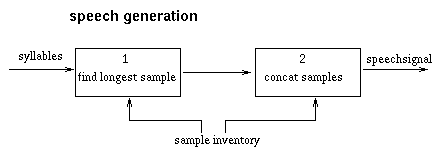
Schritt 1: find longest sample
Dies ist im Prinzip derselbe Algorithmus wie bei der Phonemisierung.
Eine Liste der vorhandenen Samples im Sampleverzeichnis wird erstellt
und mit der gerade anliegenden Silbe verglichen.
Gibt es die Silbe, wird sie an das Sprachsignal angehängt,
ansonsten, wird der letzte Laut abgeschnitten und nur der Anfang
gesucht.
Dieses Verfahren hat den Vorteil, dass es nicht auf ein spezielles
Sampleinventar angewiesen ist, sondern mit jedem (beliebig zu
erweiterndem) Inventar klarkommt, angefangen mit einem Phoninventar.
Es ist oft unnötig, ganze Silben zu verketten, silbenfinale Plosive
und auch einige Frikative können problemlos extra angehängt
werden. (z.B. für /kOx/ wird /kO-x/ verkettet).
Schritt 2: concat
Hier werden die gefundenen Samples miteinander verkettet, es gibt keinerlei
Glättung an den Grenzen und auch keine Nachbearbeitung (etwa zur
Prosodiesteuerung oder Akzentuierung).
Erstellen des Inventars
Erstellen des Silbeninventars
Das Silbeninventar wird mit Hilfe einer Vergleichsliste von
bereits transkribierten und silbifizierten Wörtern erstellt.
Das Programm geht die Liste durch, transkribiert die Wörter
und vergleicht mit der in der Liste vorgeschlagenen Lösung.
Gibt es einen Unterschied, wird der Bearbeiter aufgefordert,
diesen zu beheben (bzw. zu ignorieren).
Er muss dazu in der Regel alle noch unbekannten Silben
definieren.
Man muss sich dabei oft Gedanken darüber machen, wie man eine
Silbe überhaupt definiert;
Erstellen des Sampleinventars
Das Sampleinventar wurde mit Hilfe einer Menge von gelabelten Samples
natürlichsprachiger Wörter erstellt.
Es gibt dazu ein TCL-Script, das die phonetischen Einträge der
Konversionstabelle mit den Labeln der Samples vergleicht.
Findet es ein Wort, in dem der gesuchte Eintrag vorkommt, wird
die Stelle mittels ESPS-Tools ausgeschnitten und dem Sampleinventar
hinzugefügt.
Die einzige Regel, die es dafür gibt, lautet:
"trenne nicht Vokale nach Vokalen", um Probleme mit Diphtongen zu
vermeiden.
Weitere Regeln wären sinnvoll, da es wegen der Koartikulation
einen grossen Unterschied macht, wo man trennt (Plosive z.B. eignen
sich recht gut als Grenzen), sind aber aufwendig zu implementieren,
da man mit Preferenzen arbeiten müsste (trenne vorzugsweise
vor Plosiven).
Viel besser als ein natürlichsprachiges Inventar würde sich
ein mit gleichmässiger Stimme (ohne Grundfrequenz-, Dauer- und
Lautheitsschwankungen) gelesenes Inventar eignen, aber ein solches
stand mir nicht zur Verfügung.
Um wenigstens die Grundfrequenzschwankungen einigermassen abzufangen,
habe ich die Samples dann mittels ESPS-Tools auf eine
gleichmässige Grundfrequenz von 200 Hz durch ein
LP-Psola-Verfahren gebracht, das Ergebnis ist aber sehr schlecht,
da die Signale durch die Resynthese sehr künstlich klingen
und zudem die GF-Schwankungen so gross waren, dass das Verfahren viele
Fehler gemacht hat.
Quellcode in tcl/tk (2.6 Mb)
Gebraucht wird
-
eine Konversionstabelle (in der oben angegebenen Form),
die <units> heissen muss und in der zumindest alle einzugebenden Zeichen
definiert werden
- ein Verzeichnis namens <data> mit Samples im raw-Format mit der
Benennung <Aussprache der Lautfolge>.raw
- eine Datei namens <nouns>, die leer seien kann, aber auch eine
beliebige Liste zu trennender Wörter enthalten kann, wobei auf
die Reihenfolge geachtet werden sollte, da das jeweils erste passende
genommen wird.
demo Wav-file
(95kB)
mail: Felix Burkhardt
[main]